A new economic model is taking shape
Cloudflare sees over 200 trillion Internet interactions every single day. The data from Q1 2026 tells a story of rapid transition — from a human-centric Open Web to a machine-centric Programmable Web — and the emergence of a new content economy built on permission, attribution, and value exchange. AI is not the enemy of the web. It is the forcing function for a better deal.
AI crawler share grew 4.2 percentage points quarter-over-quarter, from 17.5% in Q4 2025 to 21.8% in Q1 2026. That growth represents enormous demand for publisher content — demand that is increasingly being channelled into formal licensing agreements. The question is no longer whether AI companies will pay for content. The question is whether publishers have the tools to set the terms. That infrastructure exists now.
"The web is becoming programmable. That is not a threat — it is an opportunity for creators to define the terms on which their work powers the next generation of the Internet."
— Matthew Prince, CEO, CloudflareThe Great Divergence
The fundamental collapse is not hard to find in the data. The bot category breakdown tells the story of a web that has pivoted away from human utility:
Bot Traffic by Category — Q1 2026 vs Q4 2025
| Category | Q4 2025 | Q1 2026 | Change | Share |
|---|---|---|---|---|
| Search Engine Crawler | 36.3% | 31.1% | ▼ −5.2pp | |
| AI Crawler | 17.5% | 21.8% | ▲ +4.2pp | |
| SEO & Analytics | 12.2% | 13.3% | ▲ +1.1pp | |
| Advertising & Marketing | 13.0% | 10.6% | ▼ −2.4pp | |
| Page Preview | 6.6% | 6.6% | → flat | |
| Monitoring & Analytics | 3.6% | 3.7% | ▲ +0.1pp | |
| AI Search | 2.2% | 3.2% | ▲ +1.0pp | |
| Webhooks | 2.5% | 3.1% | ▲ +0.6pp | |
| Aggregator | 2.7% | 2.5% | ▼ −0.2pp |
The Top Bot Operators
Among individual bot operators, Google still commands 35.5% of all verified bot traffic — but its share dropped 6.2 percentage points QoQ. OpenAI is now the #3 bot operator on the entire Internet, at 9.5%, and growing.
AI Services Are Now Internet Infrastructure
One measure of how deeply AI has embedded itself in the Internet: ChatGPT is the #8 most-trafficked service globally, ahead of Amazon Shopping, TikTok, and Netflix. It is the #12 most-visited domain in the world.
Note: Lower rank number = higher traffic. Y-axis inverted. Source: Cloudflare Radar Internet Services.
DeepSeek surged from #9–10 in the AI ranking to #4 in the single week of February 2, 2026 — immediately following global attention on DeepSeek-R1. A single model release can reshape the entire competitive landscape within days.
The Asymmetry of Extraction
The core dysfunction of the current AI web is not that bots exist — it's that they consume without reciprocating. Among all AI bot crawl activity in Q1 2026:
89.3% of all AI crawler requests are extractive, consuming content to build models that may eventually route around the source entirely. Only 8.1% powers a search product that sends users back to original content.
The Individual Crawler Pecking Order
The individual crawler ranking reveals the precise hierarchy of extraction. These are the ten most active crawlers on the web, ranked by share of all crawler traffic:
| # | Crawler | Operator | % of Crawlers | Volume |
|---|---|---|---|---|
| 1 | Googlebot | 23.7% | ||
| 2 | GPTBot | OpenAI | 17.0% | |
| 3 | ClaudeBot | Anthropic | 14.4% | |
| 4 | Meta-ExternalAgent | Meta | 12.6% | |
| 5 | BingBot | Microsoft | 7.9% | |
| 6 | Amazonbot | Amazon | 5.3% | |
| 7 | FacebookExternalHit | Meta | 3.1% | |
| 8 | YandexBot | Yandex | 2.6% | |
| 9 | PetalBot | Huawei | 2.5% |
GPTBot and ClaudeBot together account for 31.4% of all web crawler traffic — nearly a third of the entire crawler ecosystem — yet the referral products attached to them remain nascent. They consume at the scale of Google; they return traffic at a fraction of it.
The Industry Heatmap: What AI Is Actually Consuming
Cloudflare Radar data on AI bot vertical distribution reveals which industries are most exposed — and what kind of content they should be protecting.
What Each Vertical Should Protect
| Vertical | AI Crawl Share | Primary Content at Risk |
|---|---|---|
| Shopping & Retail | 31.1% | Product descriptions, pricing, imagery, reviews |
| Internet & Telecom | 16.7% | Infrastructure docs, API references, technical content |
| Computer & Electronics | 14.9% | Technical documentation, code, specs |
| News, Media & Publications | 9.2% | Articles, analysis, journalism — highest text quality per request |
| Business & Industry | 5.1% | B2B content, industry reports, market data |
| Travel & Tourism | 4.0% | Listings, reviews, itineraries, pricing |
| Finance | 2.9% | Market data, financial reporting, disclosures |
Shopping and retail is the most-crawled category at 31.1% — not because consumers are using AI to shop (yet), but because product data is rich training corpus for AI models that aim to assist with purchasing decisions. The crawl happens long before any agentic commerce product launches.
News and Media accounts for 9.2% of AI crawl activity — a figure that understates the impact. A retail product description is one sentence. A news article is thousands of words of structured, fact-checked prose. The training value per crawl request is not equal.
The ability to credibly control access is what makes content a licensable asset. Publishers who can define who accesses their content, at what terms, and verify compliance — have something concrete to bring to a negotiation. Cloudflare's enforcement layer is what converts that capability from a policy statement into a technical reality.
From Robots.txt to Honest Bot Detection
Publishers are responding with the only tool most of them have: a 47-year-old text file. GPTBot and ClaudeBot are the most restricted crawlers in the robots.txt ecosystem. In Cloudflare's verified bot catalog, 37 of 200 tracked bots are now AI crawlers or AI assistants — a category that barely existed two years ago.
Why Robots.txt Is Not Enough
First: compliance is voluntary. Our AI crawl timeseries shows that AI bot traffic hit its single-day peak of Q1 2026 on February 9 — even as blocking rates have been rising throughout the quarter. Volume is growing faster than restrictions can contain it.
Second: shadow scrapers exist. Our data shows 0.44% of AI bot crawl activity comes from bots declaring no purpose — Undeclared crawlers operating without transparency. These are bots that deliberately misidentify themselves, wearing a Googlebot mask to crawl as if they have permission they have not sought.
Third: the past is already gone. Models trained on data crawled before publishers erected their defenses have already consumed that content. The window of prevention is partly closed.
Web Bot Auth: Cryptographic Verification
This is why Cloudflare built Web Bot Auth — a new standard using cryptographic signatures to verify a bot's identity at the protocol level. If a bot claims to be Googlebot, it signs its requests with a key only Google holds. If the signature fails, the claim is false. Web Bot Auth does not rely on bots choosing to be honest; it makes dishonesty technically detectable.
AI agents — bots that actively browse, fill forms, and execute tasks — currently represent 0.16% of verified bot traffic. Small today, but the fastest-growing subcategory. These agents cannot be managed with robots.txt alone. Cryptographic identity is the necessary infrastructure for the Programmable Web.
AI Search: A New Referral Ecosystem
The AI Search category — crawlers attached to AI-powered search products that do return traffic to original sources — is one of the most strategically important in the ecosystem. It grew 1.0 percentage point QoQ — the fastest-growing bot subcategory this quarter.
| Operator | Share of AI Search Traffic | Product |
|---|---|---|
| Apple | 58.8% | Applebot → Siri, Spotlight, Apple Intelligence |
| OpenAI | 41.0% | OAI-SearchBot → ChatGPT Search |
| Cloudflare | 0.13% | Cloudflare AI Search |
| Brave | 0.07% | Brave Search AI |
Apple is the dominant AI search crawler, driven by Applebot's role in powering Siri and Apple Intelligence. Apple's crawl activity was highly volatile in Q1 2026 — near zero on some days, spiking by late March — suggesting active product development. A company with 2.35 billion active devices and a first-party AI search product is a fundamentally different referral engine than anything that preceded it.
OAI-SearchBot spiked noticeably during peak AI news periods (Jan 22–24, Feb 9, Mar 10–11), suggesting its crawl intensity tracks closely with ChatGPT usage surges. As AI search products mature and publishers begin demanding referral as a condition of access, this is the category that matters most.
The AI Agent Layer: From Crawlers to Action
The most nascent but strategically significant development is the emergence of AI assistants as a distinct traffic category. These are not crawlers passively indexing content — they are agents actively executing tasks: browsing pages, filling forms, clicking buttons, completing purchases.
| Operator | Share of AI Assistant Traffic |
|---|---|
| OpenAI | 86.0% |
| Cloudflare (Browser Rendering) | 10.7% |
| DuckDuckGo | 2.5% |
| Mistral AI | 0.26% |
| Meta | 0.25% |
| Manus | 0.22% |
| Amazon | 0.03% |
| Devin AI | 0.03% |
The 21 verified AI assistant bots in our catalog include Amazon Bedrock AgentCore Browser (deployed across 9 AWS regions), Amazon's "Buy For Me" agent, Devin AI, CartAI, Apify, and Browserbase.
An agent that can complete a purchase on a user's behalf represents a new distribution channel — one where publishers and developers who establish the right integrations will be present at the moment of action, not just the moment of discovery. The shift from crawl-and-display to act-on-behalf creates new surfaces for attribution, licensing, and value exchange that do not exist in the search paradigm.
The AI Inference Economy
Beyond what bots consume, Cloudflare's AI inference data reveals what developers are building on top of AI infrastructure in Q1 2026.
Top Models by Deployment
| # | Model | Share of Inference Accounts | Volume |
|---|---|---|---|
| 1 | Meta Llama 3 8B Instruct | 40.6% | |
| 2 | Stable Diffusion XL 1.0 | 13.4% | |
| 3 | Whisper (OpenAI) | 8.3% | |
| 4 | Meta Llama 4 Scout 17B | 7.0% | |
| 5 | M2M-100 1.2B (Translation) | 5.4% |
Text generation dominates at 62.9% of all AI inference, confirming that the primary use of AI infrastructure is language. Meta's Llama 3 is the most widely deployed model on Cloudflare's network at 40.6% of all inference accounts — Meta's open-weight strategy has produced the Internet's most-used inference model. The newly released Llama 4 Scout already accounts for 7.0% of inference accounts despite launching during the quarter — the fastest adoption curve we have observed for any new model.
Bot Management: Cloudflare's Defense Layer
The data in this report — crawl volumes, intent classification, shadow scrapers, verified identities — doesn't surface without infrastructure. Cloudflare's Bot Management platform is the layer between publishers and the automated web, scoring every request with a bot probability, a purpose classification, and an enforcement decision. At the scale of 200+ trillion signals per day, this is not a feature. It is the operating system of the Programmable Web.
How Bot Management Works
Every request that passes through Cloudflare receives a bot score from 1 to 99. Scores near 1 indicate automated traffic; scores near 99 indicate human. This score is derived from a multi-layered detection stack that runs at the edge without adding latency:
Models trained on Cloudflare's global traffic continuously classify requests against billions of known-good and known-bad behavioral patterns.
200+ verified bots — Googlebot, GPTBot, ClaudeBot, OAI-SearchBot — confirmed by reverse IP/DNS lookup. Known-good bots pass; impersonators are flagged immediately.
Request timing, TLS fingerprints (JA3/JA4), HTTP/2 settings, and header ordering expose non-human sessions even when user agents claim otherwise.
For ambiguous scores, Cloudflare's smart challenge validates humans without friction. Automated sessions that evade passive detection fail the challenge.
The next layer: bots sign requests with a private key only their operator holds. If a crawler claims to be Googlebot but fails the signature check, it is lying. No policy can be gamed.
AI Crawl Control: Publisher Enforcement at the Edge
The most consequential Bot Management capability for publishers in Q1 2026 is AI Crawl Control — purpose-built tooling for per-operator access policy on AI bots. Unlike robots.txt, which is a voluntary convention any bad actor can ignore, AI Crawl Control enforces access decisions at the network edge before content is ever served.
Cloudflare data shows AI crawl traffic hit its single-day peak of Q1 2026 on February 9 — even as publisher blocking rates have been rising throughout the quarter. Volume growth is outpacing restriction. The 0.44% of AI crawl traffic classified as "Undeclared" operates with no stated purpose and no user agent honesty — deliberately rotating identities to slip through text-file defenses. A text file on a server is not enforcement. Edge-level bot scoring is.
AI Crawl Control lets publishers set distinct rules per crawler identity — allowing OAI-SearchBot (which drives referral traffic back to the source) while blocking GPTBot (which trains models without reciprocation) on the same domain. Publishers can say, for the first time: you may index, but you may not train.
Shadow scrapers preferentially impersonate Googlebot — the one crawler virtually no publisher can afford to block. A bot wearing a Googlebot mask gets through the vast majority of publisher defenses by exploiting a structural coercion: block Google, lose search. Web Bot Auth's cryptographic signature requirement closes this permanently. A crawler that cannot produce Google's private key cannot impersonate Googlebot, regardless of what it claims in its user agent string.
Bot Score Distribution — Q1 2026
Cloudflare classifies 30.5% of all web traffic as automated in Q1 2026. Within that automated layer, the distribution polarizes: most bot traffic is either clearly machine (score 1–29) or clearly human (score 80–99). The ambiguous middle — scores 30–79 — is where sophisticated evasion operates and where ML models are most actively contested.
| Bot Score | Classification | Recommended Action | Share of Traffic |
|---|---|---|---|
| 1–29 | Likely Bot | Block or challenge | 24.1% |
| 30–49 | Possibly Bot | Challenge with Turnstile | 2.8% |
| 50–79 | Ambiguous | Log, monitor, apply additional signals | 3.6% |
| 80–99 | Likely Human | Allow | 69.5% |
Crawler Hints: Telling Good Bots When to Come
Bot Management is not only about blocking. The other half of the problem is waste. Cloudflare's analysis of search crawler traffic found that 53% of good bot visits are wasted — crawlers revisiting pages that haven't changed since their last visit, burning compute and energy for no new information. For a category that represents over 5% of all global Internet traffic, that inefficiency has material scale: Cloudflare estimates that reducing excessive crawl could eliminate as much as 26 million tonnes of carbon equivalent per year — the equivalent of shutting down six coal-fired power plants permanently.
The root cause is structural: crawlers have no reliable signal for when content changes. Without that signal, they default to visiting pages on a fixed schedule regardless of whether anything is new. Most of the time, nothing is.
Cloudflare's Crawler Hints solves this by proactively signalling to verified search crawlers when content on a site has actually changed — and by extension, when it hasn't. Rather than waiting for a crawler to discover a change on its own schedule, Cloudflare monitors cache-status at the edge and pushes real-time update signals via IndexNow, the open protocol for content freshness notification. Crawlers receive a personalized, continuously updated map of exactly which URLs changed and when — zero load on the origin server, available on all Cloudflare plans including Free.
The mechanism works through Cloudflare's edge cache layer. When a page's content changes — detected by hash or timestamp — Cloudflare records the event and notifies participating crawlers via IndexNow. Each search engine gets its own tailored feed of what changed since its last visit, ordered by page importance (inferred from human visitor frequency). The result: crawlers spend their budget on pages that are actually fresh, and publishers get their new content indexed faster.
| Without Crawler Hints | With Crawler Hints |
|---|---|
| Crawler visits on a fixed schedule regardless of content changes | Crawler visits triggered by actual content changes, signalled in real time |
| 53% of crawl visits find no new content — wasted compute and bandwidth | Crawl budget concentrated on pages that have actually changed |
| New content may sit unindexed for days or weeks | Content changes surfaced to search engines in near real-time |
| Origin server absorbs repeated unnecessary requests | Fewer bot requests reach origin; performance and resource load improve |
| Publisher has no visibility into crawler freshness | Publisher benefits from faster indexing without any additional configuration |
Crawler Hints connects directly to the economics of the AI content market. When a licensed AI crawler has access to a publisher's content, both parties benefit if that crawler indexes fresh content efficiently — the AI company's product improves, and the publisher's content is correctly represented. Excessive recrawl of stale content wastes the licensed crawler's budget on pages it has already seen, while new articles sit unindexed. Crawler Hints ensures the deal works as intended: the crawler arrives when there is something new to read, not on an arbitrary schedule.
Crawler Hints operates within the same verified bot ecosystem as AI Crawl Control and Web Bot Auth. A crawler that is allowed under AI Crawl Control because it is a verified, licensed partner gets the benefit of Crawler Hints — efficient, timely access to fresh content. A crawler that is blocked gets neither access nor hints. The enforcement layer and the efficiency layer are the same infrastructure, applied in opposite directions depending on whether the bot is trusted.
The /crawl Endpoint: Compliant Crawling by Design
On March 10, 2026, Cloudflare launched a new Browser Rendering /crawl endpoint — a developer API that submits a starting URL and returns a full website's content as HTML, Markdown, or structured JSON, via a headless browser that automatically discovers and renders pages. It is designed for building RAG pipelines, training datasets, and content monitoring — and critically, it is built from the ground up to be a compliant, permission-respecting crawler.
Unlike the shadow scrapers and undeclared bots documented throughout this report, the /crawl endpoint is a signed agent — it cryptographically identifies itself and cannot misrepresent its identity. It respects robots.txt directives including crawl-delay, honours AI Crawl Control settings, and cannot bypass Cloudflare bot detection or CAPTCHAs. It self-identifies as CloudflareBrowserRenderingCrawler/1.0 in every request — more transparent than the vast majority of AI crawlers operating on the web today.
Key capabilities include incremental crawling via modifiedSince and maxAge parameters — meaning it skips pages that haven't changed, saving cost and reducing unnecessary load. Configurable crawl depth, URL patterns, and page limits give operators precise control over scope. Static mode (render: false) fetches HTML without a headless browser for faster crawls of non-JS sites. Available on both Free and Paid plans.
Some publishers raised concerns in the days following launch — specifically that the crawler's user agent was not yet listed in Cloudflare's Verified Bot catalog, meaning bot management rules keyed to that catalog required a manual update to explicitly reference it. Cloudflare clarified the behavior in an edited changelog post and the path to blocking it for any publisher who chooses to is straightforward: the crawler identifies itself honestly, which is precisely what makes it possible to block with a simple firewall rule. That is the opposite of the problem posed by shadow scrapers that rotate identities to evade detection.
The broader point is significant: the /crawl endpoint represents what compliant AI crawling should look like. It is honest about its identity. It respects publisher signals. It cannot impersonate other bots. Every AI company operating a crawler should be held to the same standard — and Cloudflare's infrastructure is what makes that standard enforceable at scale.
From Defense to Access Control Infrastructure
The strategic shift underway is this: Bot Management is no longer purely a security product. It is the access control layer for a new content economy. Block the bad actors. Challenge the ambiguous. Signal the verified good ones to crawl smarter. The /crawl endpoint is a blueprint for what the well-behaved automated web looks like: identified, transparent, and operating within publisher-defined terms. Publishers who use Cloudflare's bot infrastructure are not just protecting their content — they are creating the conditions for productive partnership. Granular identity enforcement at the edge is what makes tiered access possible: free for search, licensed for training, auditable for both. The deal is only as good as the infrastructure beneath it — and that infrastructure now exists.
The Attribution Dashboard: Your Negotiating Brief
The existing Cloudflare AI bots dashboard tells you which bots are hitting your site and whether they are being blocked. The new Attribution Overview goes further — it turns bot management data into a deal-ready evidence base. These are the capabilities that are new, and why each one matters for licensing leverage.
Bot View — Operator-Level Attribution
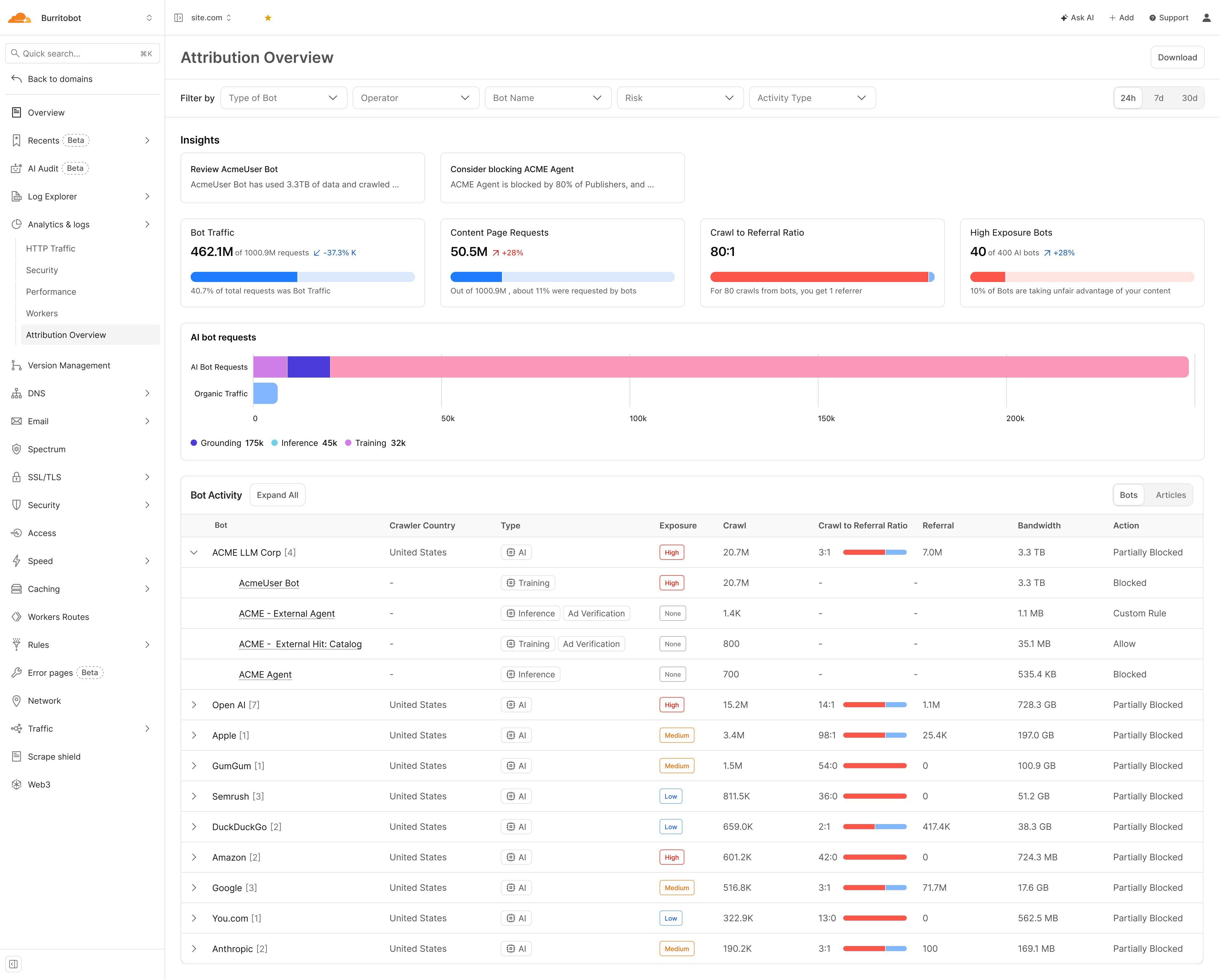
The original dashboard shows crawl volume. The Attribution Overview shows what you get back. The crawl-to-referral ratio — how many AI crawl requests it takes to produce one human referral visitor — is the single metric that quantifies the imbalance of extraction. An operator with an 80:1 ratio is taking 80 times more than it returns. A 42:0 ratio means it is returning nothing at all. This number did not exist in the previous dashboard. It belongs at the top of every negotiation brief.
The original dashboard classifies bots broadly. The Attribution Overview classifies the purpose of each visit: Training (content used to build the model — the highest-value use), Inference (query-time retrieval), or Grounding (factual anchoring in AI responses). An operator crawling for Training is building its product on your journalism. An operator crawling for Inference is using your content to answer user queries. Each has a different commercial value — and the licensing price should reflect which category applies. The dashboard makes this visible, per operator, continuously.
The original dashboard counts requests. The Attribution Overview measures data transfer in gigabytes and terabytes per AI operator. This matters because bandwidth is the unit cloud providers use to charge for egress — it is an established commercial metric, not an abstract count. When an operator's consumption is expressed in terabytes, it arrives at the negotiating table with a number already attached. "You consumed X TB of our content last quarter" is a different opening than "you sent us a lot of requests."
The Insights panel surfaces market intelligence alongside your own data: which bots your peers have blocked, at what rate, and why. When a bot is flagged as blocked by the majority of publishers in the network, that is not just a recommendation — it is evidence of industry consensus about that operator's behaviour. This context changes the negotiation dynamic: a publisher blocking a bot that 80% of peers have also blocked is acting with the weight of the market behind them.
The Attribution Overview automatically classifies bots by exposure risk — High, Medium, or Low — based on the combination of crawl volume, intent type, and referral return rate. High Exposure bots are those taking content at scale without meaningful reciprocation. This classification did not require manual analysis in the previous dashboard. It surfaces automatically, giving publishers an immediate view of which operators present the highest unlicensed extraction risk.
The Action column (Blocked, Partially Blocked, Allow, Custom Rule) existed in the original dashboard. In the Attribution Overview context it gains a new dimension: it is the negotiation starting position. When an AI company comes to the table, a publisher can show exactly how that operator is currently being treated — and name the specific terms under which the status changes. Moving a row from Blocked to Allow is the deal. The dashboard makes that concrete.
Articles View — Content-Level Attribution
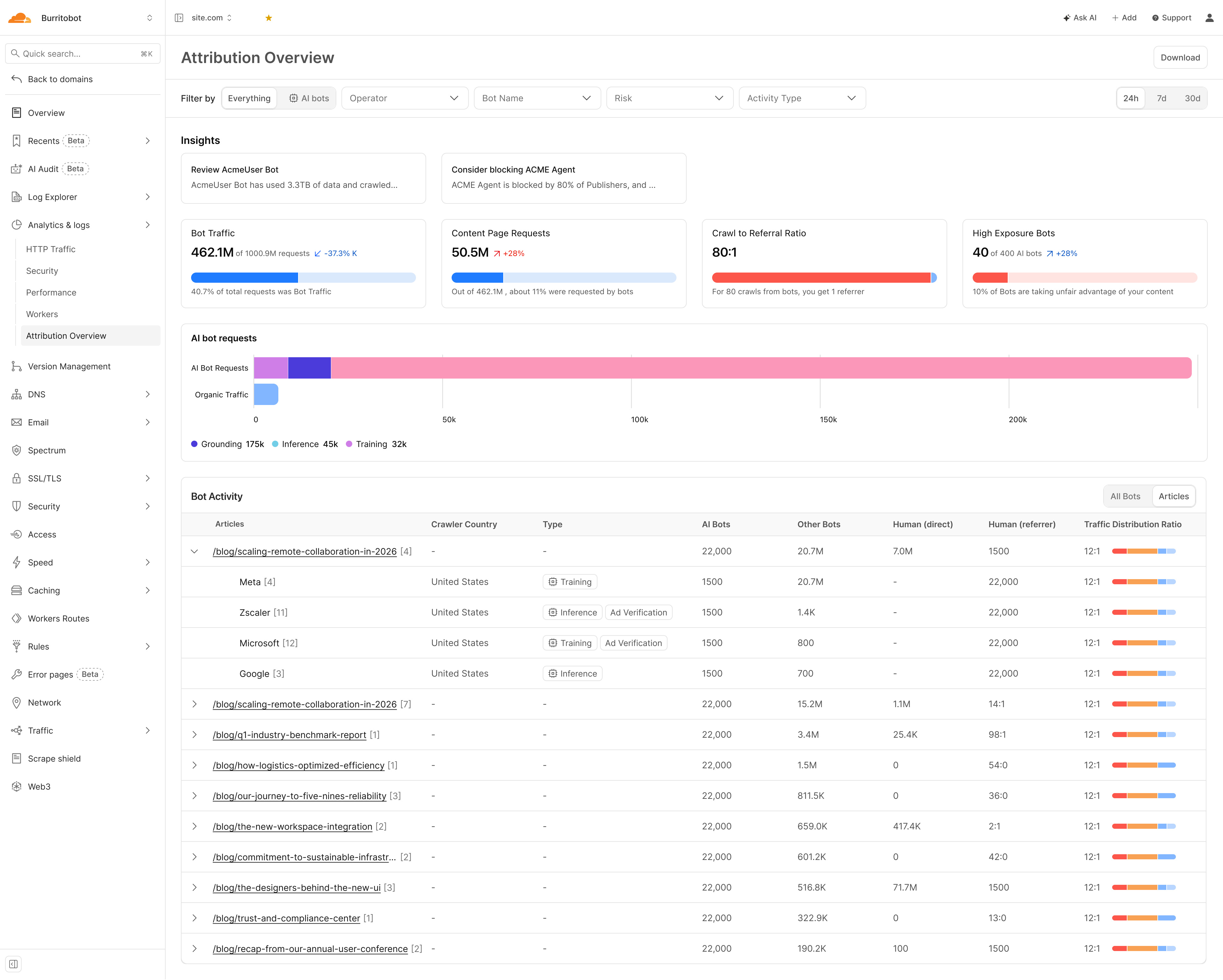
The Articles view is entirely new. It answers the question AI companies least want publishers to ask: which of my articles specifically are you training on? Each URL shows which operators crawled it, what their intent was, and how AI bot traffic compares to human traffic on that page. An article with a high AI-to-human ratio is not generating audience — it is generating training data. That distinction has a price, and the Articles view makes it visible at the content level for the first time.
Each article row shows the full traffic breakdown: AI bots, other bots, human direct, and human referral, with a colour-coded distribution bar. This is the publisher's content inventory in commercial terms — the specific URLs an AI company has been trying to access, the volume at which they have been trying, and what the crawl-to-referral ratio looks like for each piece. In a deal negotiation, this is the product catalogue. Knowing which content an operator most wants is knowing where the leverage is.
A licensing agreement that cannot be audited is a handshake. Once an operator moves from Blocked to Allowed, the Attribution Dashboard — and the Articles view in particular — becomes the ongoing record of what they access, at what volume, with what intent, article by article. This is the consumption metering layer that pay-per-use deals require to function. Without it, there is no way to verify that an AI company is honouring what it agreed to. With it, the deal has verifiable, continuously tracked terms.
Monetization: The Publisher-AI Deal Economy
The data has produced a market. Since the first publisher-AI deal in July 2023, a licensing economy has grown from a handful of bilateral experiments into 50+ documented agreements across OpenAI, Google, Perplexity, Microsoft, Meta, Amazon, Mistral, and Prorata — spanning wire services, national newspapers, magazines, specialist publishers, and collective licensing pools. The market is moving quickly, and the commercial models that will define it are being shaped right now.
"We are very happy with either model — both can be viable as long as our content is respected and paid for."
— Neil Vogel, CEO, People Inc. (Dotdash Meredith)Complete Deal Timeline: 2023–2026
Every confirmed publisher-AI content licensing deal, in chronological order. Covers training data licences, RAG/retrieval integrations, revenue-share programs, and platform-specific content marketplaces.
| Date | Publisher(s) | AI Company | Key Terms |
|---|---|---|---|
| Jul 2023 | Associated Press | OpenAI | Licence for AP archive back to 1985 for training; exploring generative AI use cases in news products |
| Dec 2023 | Axel Springer (Politico, Business Insider, Bild, Welt) | OpenAI | Content summarised in ChatGPT globally including paywalled content, with links; permitted for training |
| Mar 2024 | Le Monde, Prisa Media (El País) | OpenAI | Content summaries in ChatGPT with attribution; permitted for model training; multi-year revenue |
| Apr 2024 | Financial Times | OpenAI | Current + archive FT content for real-time queries and training; reported $5–10m/year |
| Apr 2024 | Axel Springer | Microsoft | Expanded partnership: AI chat experiences, advertising (Chat Ads API), Azure cloud migration |
| May 2024 | Dotdash Meredith (People, Investopedia, 40+ titles) | OpenAI | Real-time content in ChatGPT; content used for training; helps build D/Cipher AI ad tool; $16m+ |
| May 2024 | Informa (B2B) | Microsoft | Non-exclusive data access to 2027; $10m+ first year; Copilot for M365, specialist AI agents |
| May 2024 | News Corp (WSJ, NYP, The Times, The Australian, Barron's, MarketWatch) | OpenAI | Five-year content licence including training + real-time use; reported $250m+ over 5 years |
| May 2024 | The Atlantic, Vox Media | OpenAI | Archive journalism in ChatGPT with attribution; access to OpenAI tech for product development |
| Jun 2024 | TIME | OpenAI | Multi-year; OpenAI gets access to TIME's 101-year archive and current reporting |
| Jul 2024 | TIME, Der Spiegel, Fortune, Entrepreneur, The Texas Tribune, Automattic | Perplexity | Revenue-share program; publishers share ad revenue when content referenced in AI results |
| Aug 2024 | Financial Times, Axel Springer, The Atlantic, Fortune | Prorata | Content licensed to Prorata's Gist.ai; 50% revenue share proportional to content contribution |
| Aug 2024 | Condé Nast (Vogue, Wired, Vanity Fair, GQ, The New Yorker) | OpenAI | Multi-year; content in ChatGPT with attribution; offsets declining search traffic revenue |
| Oct 2024 | FT, Reuters, Axel Springer, Hearst, USA Today Network | Microsoft | Named partners for Copilot Daily news summaries; pay-per-use marketplace model |
| Oct 2024 | Hearst (20+ magazines, 40+ newspapers) | OpenAI | US content in ChatGPT with citations and direct links; includes Esquire, Cosmo, Elle, Houston Chronicle |
| Oct 2024 | Reuters | Meta | First news publisher Meta deal; real-time Reuters content in Meta AI across Facebook, WhatsApp, Instagram |
| Nov 2024 | DMG Media (Mail, Metro, i), Sky News, The Guardian, Prospect | Prorata | Content licensing + equity investment (DMG); first UK publishers in Prorata's platform |
| Nov 2024 | Washington Post | OpenAI | Summaries + links in ChatGPT; explicitly does not cover LLM training use |
| Dec 2024 | The Independent, LA Times, Lee Enterprises, Adweek, Blavity, DPReview, Gear Patrol, MediaLab, Mexico News Daily, Minkabu Infonoid, NewsPicks, NTV (RTL), Prisa Media, Stern (RTL) | Perplexity | Revenue-share program expansion; ad revenue sharing, API access, free Enterprise Pro for one year |
| Dec 2024 | Future plc (Tom's Guide, PC Gamer, TechRadar, Marie Claire) | OpenAI | Content partnership; Future uses OpenAI tools for sales, marketing and editorial functions |
| Dec 2024 | Lee Enterprises | Prorata | Content deal; Prorata tech helps personalise local content and automate ad processes |
| Jan 2025 | Axios | OpenAI | 3-year; ChatGPT gets content with attribution + links; OpenAI funds 4 Axios Local newsrooms |
| Jan 2025 | Associated Press | Google's first AI licensing deal; real-time AP wire feeds into Gemini chatbot | |
| Jan 2025 | AFP (Agence France-Presse) | Mistral | Multi-year; 2,300 daily stories in 6 languages feed Le Chat AI assistant |
| Feb 2025 | Schibsted (VG, Aftenposten, Aftonbladet, Svenska Dagbladet) | OpenAI | Real-time news in ChatGPT with clear attribution; Schibsted gets AI engagement insights |
| Feb 2025 | The Guardian | OpenAI | Content with attribution in ChatGPT; Guardian gets OpenAI tech access for product development |
| Mar 2025 | News/Media Alliance members (incl. McClatchy, The Atlantic, MIT Tech Review) | Prorata | Opt-in licence; Prorata pays 50% of revenues driven by AI responses using member content |
| Apr 2025 | Washington Post | OpenAI | Summaries, quotes and links in ChatGPT; does not cover LLM training use |
| May 2025 | New York Times (NYT Cooking, The Athletic) | Amazon | Alexa gets NYT summaries + recipes; covers AI model training; reported $20–25m/year |
| Jun 2025 | 500+ publishers (Atlantic, Fortune, Time, Boston Globe, The Verge, Vox, Guardian, Daily Mail, Sky News, Future) | Prorata | Prorata's Gist.ai reaches 500+ licensed publishers; one of the largest AI content libraries |
| Jul 2025 | Condé Nast, Hearst | Amazon | Multi-year; content feeds Rufus AI shopping assistant |
| Jul 2025 | People Inc. | Microsoft | Pay-per-use marketplace; "a la carte" model — contrasts with OpenAI's lump-sum deal |
| Jul 2025 | Gannett / USA Today Co. (200+ local newsbrands) | Perplexity | Content in AI search + Comet browser; Gannett staff get Sonar API and Enterprise Pro access |
| Oct 2025 | Getty Images | Perplexity | Global multi-year; Getty images in Perplexity search and discovery with credits and source links |
| Oct 2025 | USA Today Co. | Microsoft | Joins Microsoft's pay-per-use AI content marketplace; Copilot first buyer |
| Nov 2025 | Associated Press | Microsoft | Joins Microsoft pay-per-use marketplace; "very early days and experimental" per AP CRO |
| Dec 2025 | CNN, Fox News, Fox Sports, Le Monde Group, People Inc., The Daily Caller, The Washington Examiner, USA Today | Meta | Meta's first publisher deals; real-time news in Meta AI with prominent linking; mixed with user-generated content from Facebook/Instagram |
| Dec 2025 | The Guardian, Washington Post, FT, Der Spiegel, El País, Folha, Infobae, Kompas, Times of India, Washington Examiner + others | AI pilot program (non-training); AI-powered article overviews on Google News pages; cash payments | |
| Mar 2026 | Reach (Mirror, Express, OK!, and 130+ regional UK titles) | Amazon | Content in Amazon Nova AI model and Alexa; usage-based compensation — not a flat fee; Reach CEO: "more visibility and control over how content is used" |
| Mar 2026 | News Corp (WSJ, NYP, The Times, The Sun, The Australian) | Meta | Multi-year; up to $50m/year for at least 3 years; archive + real-time content in Meta AI products |
| Mar 2026 | News/Media Alliance (2,200 member publishers) | Bria | Opt-in licence for NMA members; content forms foundation for new Bria enterprise AI product; recurring revenue based on usage frequency |
Sources: Press Gazette, Digiday, BuzzStream, company announcements. 2023–March 2026. Orange rows = 2025 deals. Green rows = 2026 deals.
BuzzStream's analysis of top sites appearing in ChatGPT found little correlation between having a licensing deal and frequency of AI citations. OpenAI partners broadly, but partnerships don't guarantee ChatGPT will surface that publisher's content in responses. The deal secures access and compensation — it doesn't guarantee visibility.
Google's Structural Exception
Google's approach stands apart from every other AI platform: the Associated Press is the only publisher with a confirmed deal covering LLM training data for AI Overviews, AI Mode, and Gemini. The December 2025 pilot program with The Guardian, Washington Post, and others is a non-training arrangement covering AI article overviews in Google News. Google extracts from virtually every publisher via Googlebot — and licenses from almost none. This is the structural gap at the centre of the CMA's investigation.
Two Deal Models — Different Risk Profiles
Publisher receives a flat multi-year fee in exchange for broad content access rights. OpenAI's dominant approach with The Guardian, Axios, and others. Provides revenue certainty but misaligns incentives: the AI company has paid once and can consume indefinitely. People Inc. CEO Neil Vogel: "We are very happy with either model — both can be viable as long as our content is respected and paid for."
Microsoft's approach: an "a la carte" marketplace where publishers set prices and AI companies pay per consumption event. The AP, USA Today Co., and People Inc. are participants. Prorata's Gist.ai runs a 50% revenue-share model across 500+ publishers, distributing revenue proportionally to how much each publisher's content drove AI responses. This model better aligns economic value with content consumption — and creates the architecture for a functioning market.
Four Industry Initiatives Forcing Payment
Beyond bilateral deals, publishers are forming collective structures to create negotiating leverage — and to address the transparency gap that makes individual licensing unenforceable at scale.
"Voluntary transparency commitments alone are unlikely to deliver the level of disclosure needed to support licensing and enforcement." — Eilidh Wilson, Head of Policy & Public Affairs, PPA. Without knowing which content was consumed, when, and by which model, publishers cannot price, enforce, or audit licensing agreements. The entire market depends on solving this first.
Founded by the Financial Times, The Guardian, The Telegraph, BBC and Sky News. Aims to stop publisher content being used without permission or compensation, while creating a shared industry position rather than a fragmented response. Open to publishers of all sizes.
Publishers' Licensing Services + Copyright Licensing Agency. Aggregates content across magazines, digital news, books and academic publishing into a single repository, negotiating with AI platforms at scale. Open to any publisher with an ISSN.
A technical specification that defines how AI systems interact with publisher content at the protocol level. Sets a standardised framework for agreeing commercial terms before content is crawled — making permissions and payments machine-readable and enforceable within the infrastructure itself.
Live, opt-in model built around attribution and revenue share. Publisher content is tracked at the level of output, with compensation distributed based on usage. A working example of licensing operating at scale, combining aggregated supply with technology that assigns value to each contribution.
How Bot Management Makes Deals Enforceable
Commercial deals are only worth the paper they're printed on if the publisher can control who accesses their content. Cloudflare's Bot Management infrastructure is what converts a licensing agreement from a legal document into an enforced reality:
Cloudflare's verified bot catalog confirms that the crawler claiming to be GPTBot actually resolves to OpenAI's infrastructure. Web Bot Auth extends this to cryptographic proof. Only verified bots can be licensed. Unverified bots can be blocked.
Publishers can allow OAI-SearchBot (drives referral traffic — the paid partner) while blocking GPTBot (trains models — the unlicensed extractor). This distinction is what makes tiered licensing viable and the IAB's Content Monetisation Protocol actionable.
Publishers get visibility into which crawlers hit which pages, at what frequency, with what intent scores. This is the consumption data needed to verify that AI companies are accessing what they contracted for — and to feed pay-per-use marketplace models like Microsoft's.
The ability to credibly withhold content is what gives publisher leverage. A publisher who cannot block has nothing to sell. Cloudflare's enforcement layer converts content into a scarce, licensable asset rather than a public good freely consumed at machine scale.
The Revenue Lag — and What Comes Next
Despite the deal velocity, publisher revenue from AI licensing remains far below what search advertising once delivered at its peak. People Inc.'s Jon Roberts described the state of the market at the Digiday Publishing Summit in March 2026 as an "AI licensing boom — and a revenue lag." Deals are being signed faster than revenue is materializing.
The pay-per-use marketplace model is most likely to close this gap, because it ties compensation to actual consumption at scale. But the market infrastructure — verified identity, consumption metering, access enforcement — must exist before that pricing can be trusted. Meanwhile, publishers are running out of time to wait for legislation. The UK stepped back from an opt-out approach in March 2026, leaving space for industry-led solutions — but also leaving the field open. Publishers will have to choose a route. The clear risk is fragmentation: different collective initiatives pulling in different directions, weakening the position of all of them.
The convergence of Web Bot Auth, AI Crawl Control, and pay-per-use marketplace models represents the technical and commercial stack needed for a functioning content economy on the Programmable Web. The infrastructure is in place. The deals are being signed. The window to shape the terms of this market — as a publisher, a developer, or an AI company — is open now.
The New Deal Is Being Written Now
The data from Q1 2026 tells a story of transition — and of opportunity. AI crawler volume is growing. So is the number of licensing deals. So is the sophistication of the tools publishers have to set terms, verify identity, attribute consumption, and enforce access. The infrastructure for a new content economy is not theoretical. It is operational.
Developers building on AI are not the enemy. They are the market. The question is whether publishers can participate in that market on fair terms — and the answer, for the first time, is yes.
Cloudflare's role in this transition is to be the infrastructure layer that makes the new model work — for both sides. Bot Management and AI Crawl Control give publishers the ability to define who accesses their content and on what terms. Crawler Hints and the /crawl endpoint give developers efficient, compliant access to the web's content. Web Bot Auth gives everyone a cryptographic foundation for identity. The Attribution Dashboard gives publishers the evidence base to negotiate from a position of knowledge rather than assumption.
The Programmable Web is being built. Cloudflare is building the access layer that determines whether it is built on extraction or on agreement. The terms are being written now — by publishers who block, by developers who comply, and by AI companies who are discovering that a web full of licensed, attributed, fairly compensated content is more valuable than a web of dark patterns and silent scraping.
Block strategically. License intentionally. Build on agreement. The new deal is better for everyone.